Overview
The Bryq AI Proficiency Assessment measures how candidates and employees actually work with AI tools in realistic workplace scenarios — not what they know about AI in theory. It produces a scored proficiency profile across five competency dimensions, available at three levels matched to role requirements.
The assessment can be added to any existing Bryq hiring workflow alongside cognitive, personality, or other competency tests.
How It Works
Step 1 — Select the proficiency level
Before sending the assessment, you choose the level that matches your role's AI requirements. There are three levels:
- Aware — for roles where occasional, basic AI use is expected
- Functional — for roles where AI is a regular part of the workflow
- Advanced — for roles requiring autonomous, sophisticated AI application
Each level uses its own set of 25 questions calibrated to that depth of reasoning.
Step 2 — Candidates complete scenario-based questions
Candidates work through 25 realistic workplace scenarios and choose the best course of action. Questions are not trivia or definitions — they test applied judgement ("what would you do here?"). Each question has a 60-second timer. Answer options are randomised per candidate. No score is shown to the candidate on completion.
| Level | Label | Recommended Duration |
|---|---|---|
| 1 | Aware | 8 minutes |
| 2 | Functional | 10 minutes |
| 3 | Advanced | 12 minutes |
Answer options are randomised per candidate. No score is shown to the candidate on completion.
Step 3 — You receive a detailed proficiency profile
Results show a 0–100 score per dimension, a composite score, and a competency label (Poor / Average / Good / Exceptional) for each area. There is no pass/fail threshold — you receive the full profile to interpret against your role requirements.
The Five Dimensions
The assessment scores candidates across the complete lifecycle of working with AI:
| Dimension | What It Measures |
|---|---|
| AI Task Strategy | Knowing when to use AI and what to delegate vs. keep human |
| Prompting & Interaction Quality | Writing effective prompts and iterating based on AI responses |
| Critical Evaluation & Validation | Catching errors, hallucinations, and gaps in AI outputs |
| Ethical & Responsible Use | Understanding privacy, bias, IP, and regulatory boundaries |
| Workflow Integration & Output Quality | Turning AI output into polished, professional deliverables |
Scoring
Each of the 25 questions has four answer options scored on a 0–3 scale (0, 1, 2, 3). There is always one best answer (3) and one worst answer (0); the remaining two options are assigned scores of 1 or 2, and may not be unique — two options can share the same partial score. This is a Situational Judgement Test (SJT) format, which is an established psychometric method for assessing applied reasoning.
Per dimension: Raw score out of 15 (5 questions × max 3 points), converted to a 0–100 score.
Composite score: Arithmetic mean of the five dimension scores (each weighted equally at 20%).
Proficiency labels:
- Exceptional: 80–100
- Good: 60–79
- Average: 40–59
- Poor: 0–39
Important: Scores are level-specific. A score of 80 at the Aware level reflects strong performance on Aware-level questions — it does not indicate readiness for a Functional-level role. Scores are not comparable across levels.
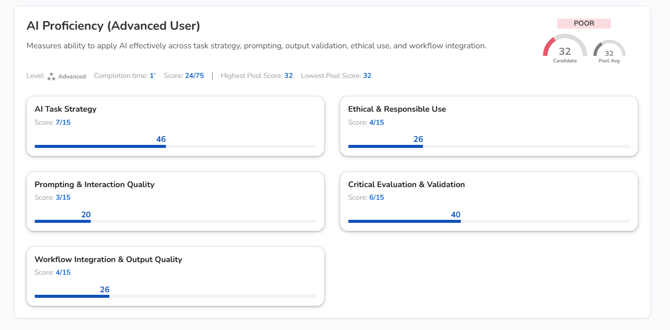
What Employers See
Under the Skills tab you will be able to view:
- A 0–100 composite score with the assessment level clearly labelled
- A five-dimension competency profile with strength labels per dimension
Research Basis
The competency framework is built on six peer-reviewed research sources covering international government frameworks (including UNESCO and UK Government), academic competency models, and policy-grade workforce research (including SFIA and the Digital Education Council). Each dimension maps to established AI literacy and digital skills scholarship. The assessment is validated using standard psychometric methods.
Key Characteristics
- Tool-agnostic — not tied to ChatGPT, Copilot, or any specific product
- Role-universal — applicable across any function or seniority level
- No pass/fail — outputs a proficiency profile, not a binary result
- Combinable — can be run alongside any other Bryq assessment in the same session
- Fairness — scenarios use common workplace contexts with no domain-specific knowledge required; no cultural, gender, or age biases are embedded
Frequently Asked Questions
Is this assessment specific to any AI tool? No. The assessment is tool-agnostic. It measures how a candidate reasons about and works with AI, regardless of which specific tools they use.
Does it only apply to technical or developer roles? No. It is designed for any role where AI use is relevant — including non-technical functions like marketing, HR, finance, and operations.
Is there a pass/fail score? No. The assessment returns a scored proficiency profile. You decide what threshold is appropriate for your role.
How long does it take? Approximately 12 minutes. There is no per-question timer but an overall countdown is visible.
Can I use this for current employees, not just candidates? Yes. The assessment can be used for both hiring and internal skills evaluation.
Will it become outdated as AI tools evolve? The assessment measures reasoning and judgement about AI use — capabilities that transfer across tools. Because it is not tied to any specific product's interface or features, it is designed to remain relevant as the AI landscape changes.
How does this relate to the EU AI Act? The Ethical & Responsible Use dimension covers awareness of regulatory boundaries including the kinds of obligations introduced by frameworks like the EU AI Act. The assessment does not replace compliance training but can identify gaps in relevant awareness.